

在本屆I/O大會中,我們看到了一個從未如此強大,甚至接近所謂“通用人工智能”的Google Assistantm 語音助手。
只需要用自然語言發布命令,它就可以完成過去從未想過能完成的任務;
我們還感受到圍繞Google 搜尋的新功能,帶來的前所未有的體驗創新,讓我們在國外旅行時再也不用擔心看不懂菜單、交通指示;
通過新的深度學習技巧 federated learning,用戶不需要上傳數據,就能感受到AI模型所帶來的客製化體驗。
Google將它運用到了十億級用戶的產品當中,讓我們看到它在AI的時代保護用戶數據隱私,不只是嘴上說,也有切實的行動。
AI 幫你完成重複工作
在北美工作和生活,經常在線上完成訂單的同學可能經常遇到這一情況:每次都要填寫大量的表格,輸入重複的信息,包括姓名、聯繫方式、機票時間班次、車型、帳單地址、送貨地址等,來回在各種網頁跳轉,如果在手機網頁上還要放大縮小頁面,點到表格上才能輸入……浪費了大量的時間

為什麼這類操作,不能像密碼 autofill 那樣自動完成?
Duplex on the web是Google Assistant的一個新能力。
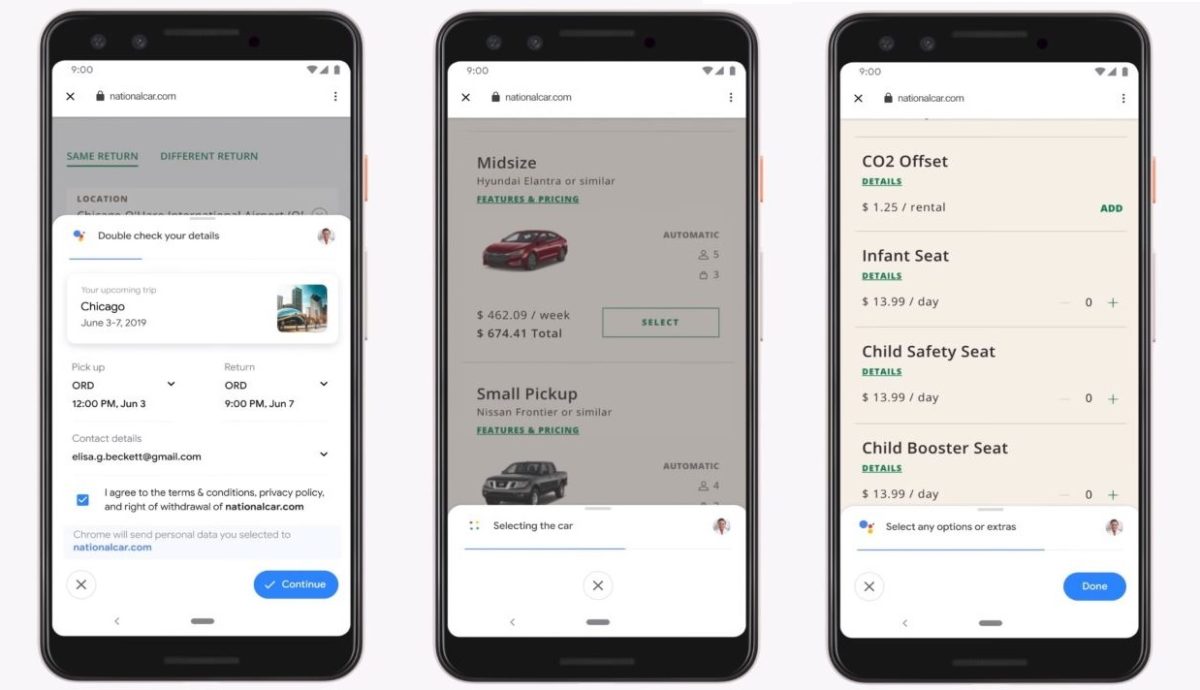
它的任務,就是幫助你在網頁上完成任何任務。不過目前,它主攻的方向是完成訂單,比如網購、租車和訂票。
比如在下面視頻中,用戶因為出差需要租車。Google Assistant
1)透過日曆了解用戶的行程、目的地和往返航班信息,
2)自動打開租車網站,確認上述信息是否正確,
3)再按照用戶以往租車習慣直接選擇車型,再次跟用戶確認,
4)最後確認整個訂單。
如果你仔細觀察,全程用戶只點了4次螢幕……四次!就下好了訂單,完成了整個租車的流程。
為什麼Google Assistant 能夠代替用戶完成這些任務?
首先,因為Google透過內部系統串接,Assistant 可以讀取用戶的Gmail、日曆以及保存好的付款資訊,讓用戶省去反覆輸入重複資訊的困擾。其次,Duplex on the web 本身是一項非常複雜,但在提升用戶效率上效果拔群的技術。它的核心是一個遞歸神經網絡(RNN),執行包括自然語言理解、處理、語音識別、文字轉語音、信息錄入等多種任務。
Duplex 可以模擬出一個自然聲音,替用戶給餐館、酒店或理髮店打電話,展現出了強大的自然語言計算能力。
其實,Duplex 的本質就是一個專門做“下訂單”這件事的聊天機器人。
不過,去年的Duplex 和今年的Duplex on the web 區別在於
前者的交互就是聊天,基於語音識別和自然語言處理,後者更強調讓AI 完成基於圖形界面的交互工作。
Duplex 將在今年晚些時候 於美國和英國先行推出,支援所有內置Google Assistant 的Android 手機
可以完成的任務包括租車和電影票。
無疑,如果你已經在使用Google 產品,Google 就已經拿到了你大量的數據。
在無法離開谷歌全家桶/沒有更好的替代方案前提下,我們自然會希望Google 為我們帶來更多的價值。
Duplex on the web 就是這樣一個功能,它幫助我們完成高重複性的工作,帶來了效率和體驗的提升。
更快、更聰明的Google 語音助手
今年,由於在遞歸神經網絡技術方面的進步,Google 將新版Google Assistant 背後的神經網絡模型大小從數百GB 縮小到了不到500MB。這意味著兩件事:
1)Google Assistant 終於可以不需要和雲端相連,在本地使用了;
2)正因為不需要聯網,它的語音識別、回應和完成任務的速度顯著提升了。
現場展示的效果令人震驚。隨著演示者說出命令,句子說完的一秒鐘之內Google Assistant 已經執行完畢
講者命令手機打開計算器、日曆、瀏覽器等軟體,以及約翰·傳奇的Twitter 頁面,Assistant都迅速完成了任務。
講者讓Assistant 在Google Photos 裡找到所有黃石公園的照片,Assistant 很快就找到了那些照片。
演示者又追加了一句“the ones with animal”(完整語境:黃石公園所有照片裡有動物的照片)
雖然命令裡沒有任何語境,但是Assistant 仍然正確找到照片。
當回覆郵件時,Assistant 還能理解演示者所說的話屬於郵件內文,還是 “標題:xxx”這樣的命令,並作出對應的操作。
全程,講者完全沒有觸碰螢幕,所有的動作都通過語音完成
Google 語音助手的執行能力和效率已經和 鋼鐵人的賈維斯差不多。
而且因為不需要聯網,現場的展示是在飛航模式模式下進行
Google 宣稱,因為可以在本地運行,新版Google Assistant 理解和處理請求的速度比當前版本快10倍。
不僅如此,新版Google Assistant 的自然語言理解能力比前代有很大增強,現在可以連續追加請求,不用每次都加一句”Hey Google/Ok Google”,而且還能跨應用程序完成任務。
可能是因為對手機計算性能或者特殊硬體有要求,Google宣布下一代Pixel手機才可以使用新版Assistant。
不過按照慣例,新功能發布半年到一年之後,因為Google對神經網絡模型的持續優化,老款設備應該也會支持。
對於普通人來說,Google Assistant的改進效果可能並沒有那麼顯著,畢竟大部分人都有靈活的雙手,也不一定認為語音控制就是最合適的交互方式。但是,對於雙手行動不便的障礙人士,更快的響應速度,以及對語音控制的更好支持,意味著當他們使用手機時,也可以享受AI,享受Google Assistant對生活和工作帶來的改善。
另一個名叫Live Relay的功能,在某種程度上和去年的Duplex電話機器人非常相似。它的任務是幫助聾啞人打電話。
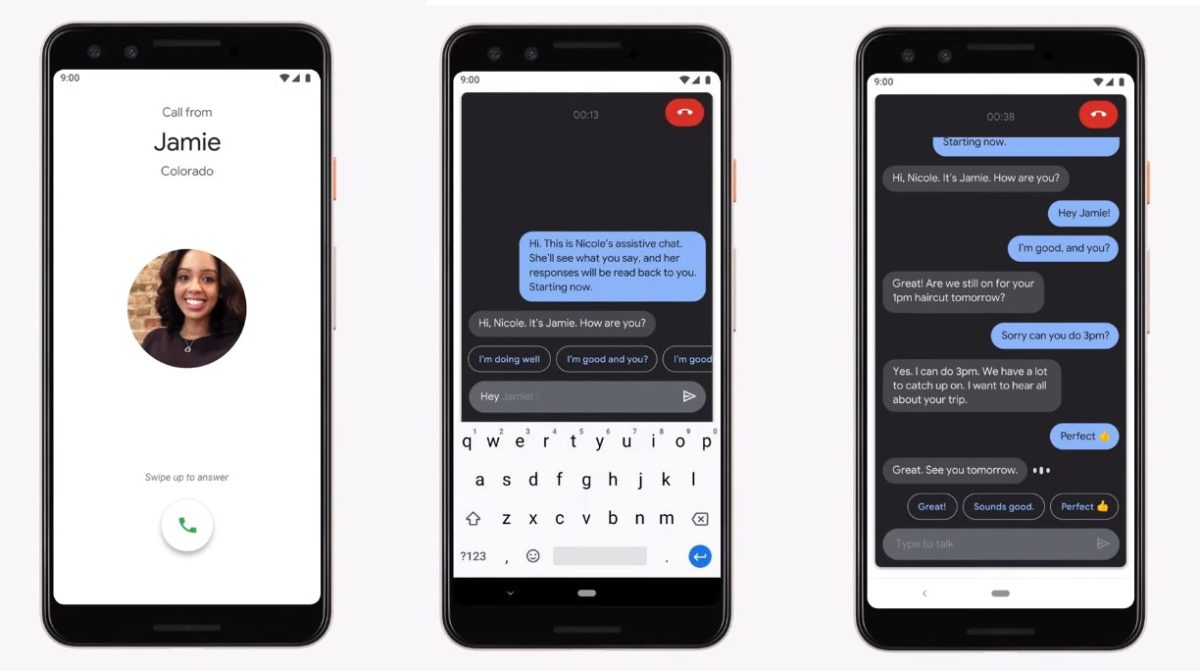
Google 遇到的一個案例是,一位以色列聾啞人怎麼都弄不好他的寬帶,但是寬帶公司除了電話之外不支持其他任何客服方式——沒有電郵、短信和打字聊天。而通過Live Relay,聾啞人獲得了一個能通過語音和對方正常交流的“代理人”,而他自己只需要打字或者用AI 生成的短語控制這個代理人即可。
有了這個技術,聾啞人也能和其他人通過電話交流了。
在這個AI 驅動技術進步的年代,AI 應當為了所有人而開發,它帶來的進步不應該只被一小部分人所感受到。“我們需要確保在神經網絡的設計中去掉偏見。”皮柴說。
如果像Project Euphonia 這樣的技術早幾十年誕生,正好趕上霍金的輝煌年代,該有多好?
讓每一位普通人的生活更輕鬆
所有人,當然也包括大部分人。儘管對障礙人士格外看重,Google 今年也沒有忘掉普通用戶。
前面提到的Google Assistant 改進、Duplex on the web 技術,其實對所有人的生活都能帶來改變。除此之外,橫跨Google 整個產品陣列,在今年的I/O 大會上都有值得一提的功能更新。
在中國市場上,包括百度在內的搜索產品整合相機拍攝功能已經有很長一段時間了。而Google 在兩年前才在手機端搜索/相機app 裡整合了Google Lens 技術。不過和同類視覺搜索產品相比,Google Lens 的進化速度未免有點快……
I/O 2019大會上,Google Lens獲得了一個許多用戶可能都用得上的功能:AR點菜……
聽到名字你可能覺得無聊,點菜就點菜,搞什麼AR?別著急,其實這個功能蠻簡單也挺有用:在餐館裡,對著一張全是文字的菜單拍照,手機會自動告訴你那幾道菜評價最好,甚至還能給你調出幾張照片,方便你點菜。

這個功能的背後,生活在西方國家或經常出國旅行的中國朋友可能都感同身受:不像中餐館喜歡放圖,很多歐美餐館菜單都是純文字,上面只有菜名和用料,更別提大部分人對用料的英文也一知半解,經常出現點完了還不知道自己在吃什麼的情況。
而這次Google推出這個功能,讓我明白了一點:原來不只是中國人,點菜對全世界人民都是個難題啊……
Google Lens 的這個功能,實現方式其實很好理解:首先用GPS 或手機信號的地理位置記錄來確認用戶所在的餐館,然後用光學字符識別之類的技術對菜單進行索引,再跟Google Maps/Yelp (美國版大眾點評)上的熱門菜品和評價進行比對,最後再把熱門菜品通過AR 技術投射在屏幕上。
以後,出門下館子再也不怕點菜了。
小票識別:在美國吃飯大家都喜歡各付各的(=中國的AA制),但也會經常遇到餐館不收多張卡的情況,再加上小費,每個人該付多少很不好算。而Google Lens現在有了一個新功能,用相機拍一下小票,Lens會自動識別金額,按照用戶希望的比例計算小費,最後再算出分單的金額——一個挺有用也挺有趣的功能。

通用隱身模式:當大家不想自己的瀏覽記錄被追踪和記錄,特別是瀏覽某些不可名狀網站的時候,都會打開Chrome瀏覽器的隱身模式(incognito mode)。
現在,Google 計劃更多的產品支持隱身模式。比方說,你臨時需要查看一個YouTube 視頻,但是不想今後自己的推薦裡出現大量類似的視頻,點一個按鈕就可以在YouTube 裡打開隱身模式。目前YouTube 已經支持,不久後Google Maps 和Google 搜索也將引入隱身模式。
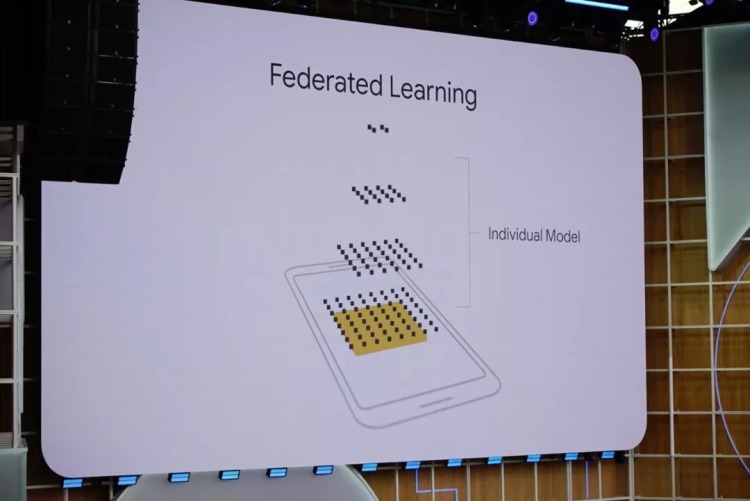
Federated Learning:簡單來說,用戶的數據不上傳,只在本地訓練訓練一個簡單的獨立模型→這個模型上傳(不攜帶可識別或不可識別的用戶數據),在雲端進行計算,整合出一個通用的模型,再下載到用戶的終端設備上。
這樣做,用戶即能感受到基於深度學習的人工智能技術帶來的好處,又避免了自己的數據被上傳。Google 透露,目前Gboard 輸入法就在採用federated learning 技巧。
Live Caption:在聲音嘈雜或情況復雜的環境裡用手機看視頻,想要聽清楚聲音是不現實的,傷耳朵,也容易讓自己失去對周遭的感知,無法避免危險情況出現。所以,我們都喜歡開字幕。

但問題是,不是所有視頻網站都有字幕功能,不是所有內容提供者都考慮到觀眾的需求添加了字幕。所以Google 做了這個功能,基於一個幾十kb 大小的模型,完全利用手機本地的計算能力,能夠對任何手機端播放的視頻媒體(Twitter、Instagram、本地視頻等)生成實時的字幕。

Live Caption 的開關在音量調節的界面裡,按一下手機音量+或者-按鈕就可以看到。該功能將隨Android Q 在今年夏天推出。
多年以來,驅動Google 進步的技術,已經從搜索變成了AI。它的用戶群也從北美和全世界的網民,逐漸擴展到了更多的人——其中包括其他發展中國家市場的非網民、文盲和障礙人士——所謂的“下一個十億”。
與此同時,它的使命卻一直沒有改變:整合全球信息,使人人都能訪問並從中受益。(organize the world’s information and make it universally accessible and useful.)
這意味著,Google 的產品和技術,必須可以被所有人使用,並且對所有人有用。而Google 在I/O 2019 上發布的諸多功能,在我看來皆是為了兌現這一承諾。
最近兩年來,Google 將“無障礙使用”(accessiblity) 作為技術創新的重中之重。如果一個產品無法被所有人所使用,那麼它可能不是一個具備同理心的產品,會導致用戶的疏遠,進而導致社群的隔閡。
讓AI對障礙人士一視同仁
在本屆I/O 上,Google 為障礙人士帶來的福利,可不止上面Google Assistant 這一條。
關注科技進展的朋友可能都聽說過,即便是在基於神經網絡的人工智能中,也存在偏見(bias)。這偏見可能來自於AI 的開發者,但更多時候原因是結構化的。比方說,作為訓練數據的有色人種照片太少,訓練出的人臉識別系統對有色人種的表現就很差。
同樣,當訓練語音識別和自然語言理解系統時,我們需要使用大量中文或者英文的高精度語料。但是,許多開發者沒有想過的是:發音障礙人士(比如聾啞人)的口頭表達能力很差,他們的發音對於普通人來說很難理解——那麼,他們就不配享受語音識別和自然語言技術進步帶來的成果嗎?
Google 顯然不這樣認為。在I/O 2019 上,該公司宣布了內部正在做的幾個專門解決此類問題的項目。
Project Euphonia 就是這樣一個項目。Google AI 的研究人員和世界上致命的“漸凍人症”(ALS)救助機構合作,了解患者對於溝通的需求和最大的渴望是什麼。研究人員將漸凍人症患者有限的語句錄下來,轉成聲譜圖的視覺形式,將它作為訓練數據餵給神經網絡。

訓練結果是顯著的。儘管Project Euphonia 還在科研階段,強化過的語音識別系統對發音障礙人士的魯棒性已經達到了商業化產品(比如YouTube 自動生成字幕)的水平。
但是,每一位障礙人士面臨的障礙千差萬別。比如深度漸凍人症患者和高位截癱患者,往往連說話的能力都被剝奪,有些人只能發出“無意義”的聲音,有些人還能做面部表情就已經是奇蹟。在過去,這些人使用互聯網,只能通過眼球追踪的鼠標/打字板,對交流形成了巨大阻礙。
針對不同的身體和認知障礙情況,Project Euphonia 的研究人員找到一種定制化AI 算法的方式,對聲音、表情進行學習,現在已經能夠準確地理解並傳遞患者想要表達的內容或者情緒,並控制電腦完成對應的操作。
在一個展示影片當中,一位十三年深度ALS 患者Steve Saling坐在輪椅上看球賽,當他支持的隊伍進球時,系統識別到了他的表情,並播放了歡呼和喇叭的音效。

同時,也協助漸凍人讓手機理解臉部語言
這次I/O上,Google還宣布了許多面向障礙人士設計的功能
比如讓為“漸凍人症”(ALS)患者的面部表情設計神經網路,從而讓機器可以理解這些障礙人士的“自然語言 ”
請看影片範例
科技以人為本,已經不只是諾基亞的口號。包括Google在內,許多頂尖科技公司的使命都和這句話有關。無論膚色、階層、國籍、身體和認知狀態,所有人都可以感受科技帶來的進步,我覺得那才是科技進步的真正意義。
發佈留言